- Từ bỏ DSP truyền thống: Khi Micro trở thành một thực thể tính toán
- Machine Learning Auto-EQ và khả năng cô lập giọng nói thông minh
- => Có thể bạn cũng quan tâm : Sự can thiệp của thuật toán Machine Learning trong thiết kế thùng loa cộng hưởng
- Giao thức Matter và tính tương hợp thiết bị (Device Interoperability)
- Thực chứng tại MyAI Sound Lab: Bài test độ trễ và ổn định tín hiệu
- Low-Latency Streaming và Cloud Audio: Tương lai của Collaboration
- => Có thể bạn cũng quan tâm : Vang số thế hệ mới sử dụng AI để tự động cân bằng dải tần (Auto EQ)
- Kết luận: Tầm nhìn về Connected Listening Experience
Từ bỏ DSP truyền thống: Khi Micro trở thành một thực thể tính toán
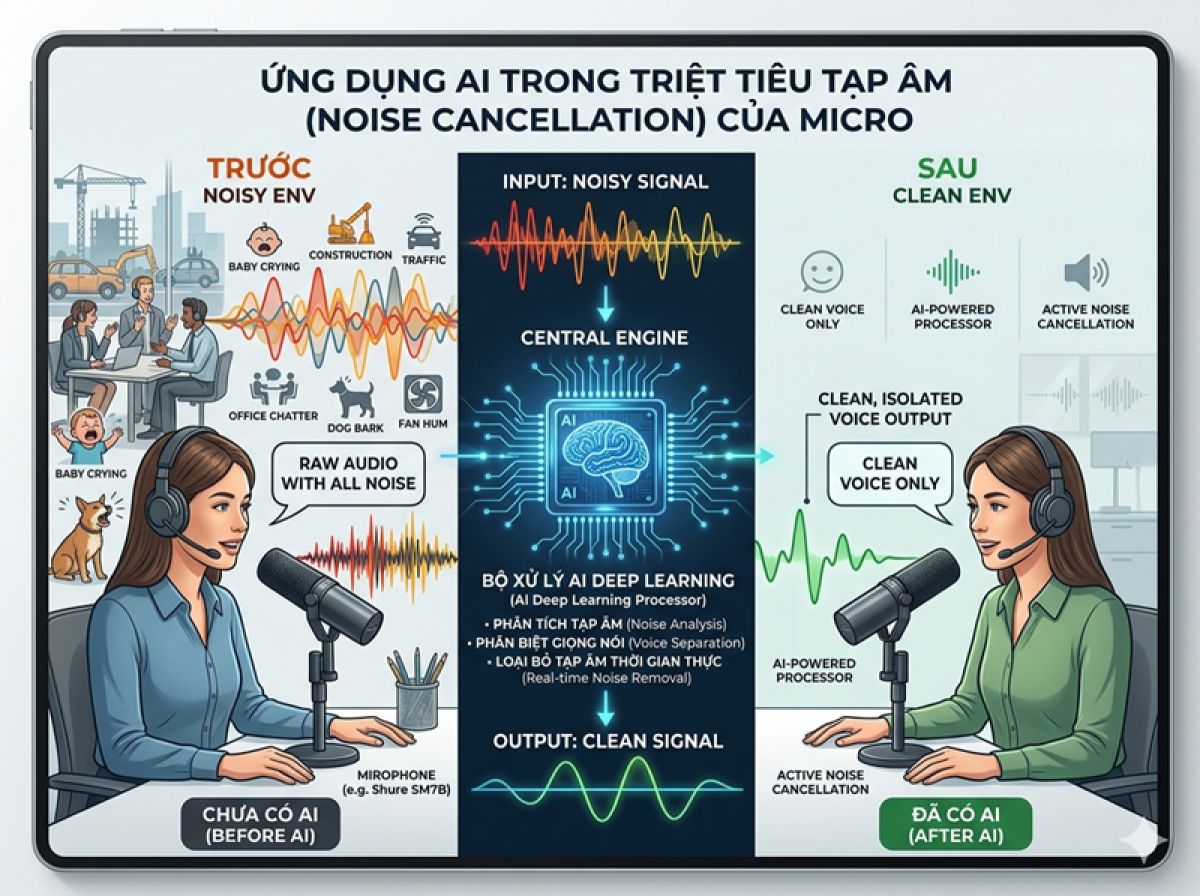
Năm 2026, chúng ta không còn định nghĩa triệt tiêu tạp âm (Noise Cancellation) là việc đảo ngược pha sóng âm đơn thuần. Tại MyAI Sound Lab, chúng tôi quan sát thấy một sự chuyển dịch mang tính cấu trúc: Micro không còn là linh kiện ngoại vi thụ động. Thay vào đó, chúng là những node xử lý dữ liệu độc lập trong mạng lưới Cloud Audio.
Sự khác biệt nằm ở việc tích hợp các dòng chip NPU (Neural Processing Unit) chuyên dụng ngay trên bo mạch của Micro. Thay vì gửi toàn bộ raw data về CPU để xử lý — gây ra mức DSP Latency không thể chấp nhận được trong các tác vụ realtime — các thuật toán Machine Learning giờ đây thực hiện "Deep Cleaning" ngay tại vùng biên (Edge). Điều này cho phép lọc bỏ tiếng ồn môi trường với độ chính xác theo thời gian thực dưới 5ms, một con số lý tưởng cho các giao thức truyền tải không dây thế hệ mới.

Từ bỏ DSP truyền thống: Khi Micro trở thành một thực thể tính toán
Machine Learning Auto-EQ và khả năng cô lập giọng nói thông minh
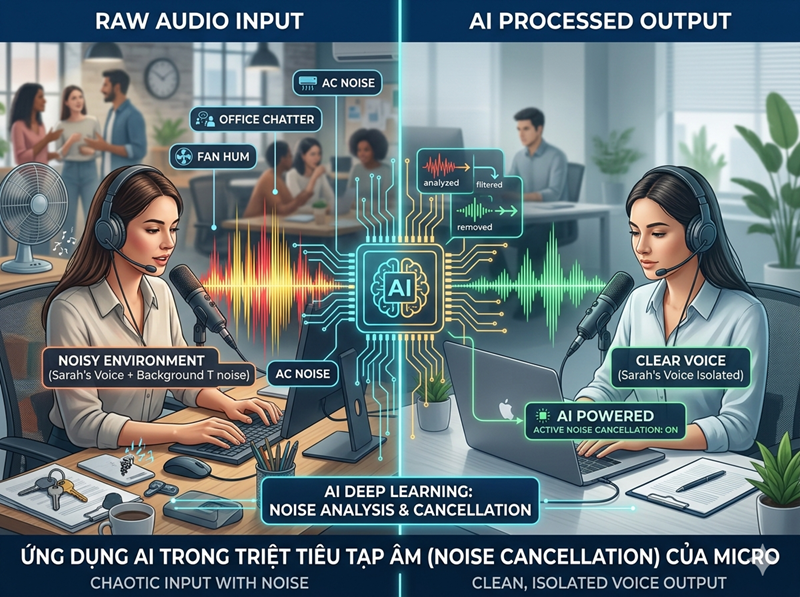
Khác với các bộ lọc thông dải (Band-pass filter) tĩnh, Machine Learning Auto-EQ năm 2026 có khả năng tự học đặc tính âm học của người dùng. Hệ thống sẽ phân tích "vân giọng" (Voice Print) và tạo ra một lớp mặt nạ động, chỉ cho phép tần số đặc trưng của người nói đi qua, đồng thời triệt tiêu hoàn toàn các tần số rác như tiếng gõ bàn phím, tiếng điều hòa, hay tiếng gió hú.
Highlight: Sự trỗi dậy của Voice-First Interface
Trong hệ sinh thái Smart Home, Micro tích hợp AI đóng vai trò là "cửa ngõ" nhận diện ý thức. Việc triệt tiêu tạp âm không chỉ để nghe rõ hơn, mà để các trợ lý ảo (AI Agent) hiểu đúng lệnh trong môi trường đa tạp âm. Độ chính xác của việc thực thi lệnh phụ thuộc 90% vào khả năng khử nhiễu tại nguồn thay vì xử lý trên Cloud.
=> Có thể bạn cũng quan tâm : Sự can thiệp của thuật toán Machine Learning trong thiết kế thùng loa cộng hưởng
Giao thức Matter và tính tương hợp thiết bị (Device Interoperability)
Một trong những rào cản lớn nhất của âm thanh chuyên nghiệp trước đây là sự phân mảnh giao thức. Tuy nhiên, với sự phổ biến của tiêu chuẩn Matter 1.4+, các thiết bị Micro AI hiện nay đã có khả năng Device Interoperability tuyệt vời.
Khi một Micro nhận diện được tiếng ồn quá lớn từ môi trường (ví dụ máy hút bụi đang hoạt động), thông qua mạng lưới Smart Home Ecosystem, nó có thể gửi tín hiệu điều khiển để giảm công suất máy hút bụi hoặc điều chỉnh Multi-room Audio sang chế độ ưu tiên đàm thoại. Đây là sự kết hợp giữa xử lý tín hiệu âm thanh và quản trị hạ tầng thông minh mà chúng tôi đang thử nghiệm chuyên sâu tại Viettel Complex.
Giao thức Matter và tính tương hợp thiết bị (Device Interoperability)
Thực chứng tại MyAI Sound Lab: Bài test độ trễ và ổn định tín hiệu
Trong tuần qua, đội ngũ kỹ sư tại Tầng 10, Tòa nhà Viettel Complex đã thực hiện một chuỗi bài test khắc nghiệt trên các dòng Micro tích hợp AI-assisted Audio Tuning.
Môi trường test: Phòng Lab mở, bao quanh bởi hơn 50 thiết bị phát Wi-Fi và Bluetooth để tạo nhiễu điện từ cực đại.
Nội dung test: Chúng tôi sử dụng giao thức Audio over Wi-Fi để truyền tải tín hiệu từ Micro đã qua xử lý AI đến hệ thống loa đa phòng (Multi-room).
Kết quả: Nhờ vào việc tối ưu hóa Firmware và cơ chế Wireless Synchronization mới, độ lệch pha giữa các node âm thanh được duy trì ở mức nanosecond. Quan trọng hơn, thuật toán Noise Cancellation vẫn giữ được độ trung thực (Fidelity) của giọng nói mà không bị hiện tượng "artifact" (tiếng vang giả tạo) thường thấy trên các dòng chip xử lý cũ.
Việc cập nhật qua OTA Update cho phép chúng tôi nạp các mô hình ngôn ngữ và mô hình nhiễu mới nhất vào thiết bị mà không cần can thiệp phần cứng, giúp hệ thống luôn tiến hóa theo thời gian.
Low-Latency Streaming và Cloud Audio: Tương lai của Collaboration
Tương lai của làm việc từ xa và giải trí số dựa trên Low-Latency Streaming. Khi tín hiệu âm thanh được "làm sạch" bởi AI, băng thông cần thiết để truyền tải giảm đi đáng kể do không phải chứa các dữ liệu nhiễu vô ích. Điều này tạo điều kiện cho các nền tảng Cloud Audio vận hành mượt mà hơn, ngay cả trong điều kiện mạng không ổn định.

Low-Latency Streaming và Cloud Audio: Tương lai của Collaboration
Highlight: Thông số kỹ thuật cần quan tâm trong năm 2026
Sampling Rate: Minimum 96kHz cho AI Model Training.
Protocol: Hỗ trợ chuẩn Matter và Thread cho kết nối năng lượng thấp.
Processing: Tích hợp NPU tối thiểu 2 TOPs để xử lý khử nhiễu đa tầng.
=> Có thể bạn cũng quan tâm : Vang số thế hệ mới sử dụng AI để tự động cân bằng dải tần (Auto EQ)
Kết luận: Tầm nhìn về Connected Listening Experience
Công nghệ AI trong Micro không đơn thuần là một tính năng cộng thêm, nó là nền tảng cho Connected Listening Experience. Khi ranh giới giữa phần cứng âm thanh và phần mềm trí tuệ nhân tạo bị xóa nhòa, người dùng sẽ nhận được một trải nghiệm trong trẻo tuyệt đối, bất kể họ đang ở trong một công trường xây dựng hay giữa quán café náo nhiệt.
Việc tối ưu hóa từ tầng Firmware cho đến giao diện UX điều khiển trên Smartphone là con đường duy nhất để các hãng công nghệ âm thanh tồn tại trong kỷ nguyên 2026.



