
- Bối cảnh và Động lực Phát triển: Từ Đơn nhiệm đến Đa nhiệm Âm thanh
- Công nghệ Cốt lõi đằng sau Trợ lý ảo Âm thanh Đa nhiệm
- Ứng dụng Thực tiễn và Tiềm năng Vô hạn
- 1. Trong Nhà thông minh (Smart Home):
- 2. Trong Xe tự hành và Xe kết nối (Autonomous Vehicles & Connected Cars):
- Thách thức và Hướng phát triển Tương lai
- 1. Thách thức Kỹ thuật:
- 2. Thách thức về Quyền riêng tư và Bảo mật:
- Xu hướng Phát triển Tương lai:
- Phân tích và So sánh: Góc nhìn Chuyên sâu
- Kết luận: Tương lai Âm thanh Đang Lắng nghe Đa chiều
Trong kỷ nguyên số hóa, trợ lý ảo giọng nói như Alexa, Google Assistant hay Siri đã trở thành một phần quen thuộc trong cuộc sống hàng ngày, giúp chúng ta thực hiện các tác vụ đơn lẻ một cách tiện lợi. Tuy nhiên, khi môi trường tương tác ngày càng trở nên phức tạp – nhiều người dùng cùng lúc, nhiều nguồn âm thanh đan xen – giới hạn của các trợ lý ảo đơn nhiệm truyền thống dần bộc lộ. Đây là lúc khái niệm Trợ lý ảo âm thanh đa nhiệm (Multi-tasking Audio Virtual Assistant) xuất hiện như một bước tiến đột phá.
Vậy, Trợ lý ảo âm thanh đa nhiệm là gì? Đó là hệ thống AI tiên tiến có khả năng không chỉ lắng nghe mà còn hiểu và xử lý đồng thời nhiều luồng âm thanh, nhiều yêu cầu từ nhiều người dùng khác nhau trong cùng một môi trường. Công nghệ này không chỉ đơn thuần là một bản nâng cấp, mà hứa hẹn sẽ cách mạng hóa cách chúng ta tương tác với công nghệ trong hai lĩnh vực then chốt: nhà thông minh và xe tự hành.
Bài viết này sẽ đi sâu phân tích các công nghệ cốt lõi đằng sau trợ lý ảo âm thanh đa nhiệm, khám phá những ứng dụng thực tiễn đầy tiềm năng, đối mặt với những thách thức kỹ thuật và đạo đức, đồng thời phác thảo bức tranh tương lai của tương tác âm thanh thông minh. Chúng tôi sẽ cung cấp những góc nhìn chuyên sâu, dựa trên các phân tích kỹ thuật và xu hướng thị trường mới nhất.
Bạn quan tâm đến những đột phá mới nhất trong lĩnh vực AI âm thanh? Đăng ký nhận bản tin từ Trung Tâm My AI Việt Nam ngay hôm nay để cập nhật những phân tích chuyên sâu và không bỏ lỡ bất kỳ xu hướng công nghệ nào!
Bối cảnh và Động lực Phát triển: Từ Đơn nhiệm đến Đa nhiệm Âm thanh

Bối cảnh âm thanh đa nhiệm và đơn nhiệm
Sự phát triển của trợ lý ảo ban đầu tập trung vào việc giải quyết các yêu cầu tuần tự, một người nói - một tác vụ. Tuy nhiên, thực tế môi trường sống và di chuyển lại hoàn toàn khác. Trong một gia đình, nhiều thành viên có thể cùng lúc muốn tương tác với hệ thống nhà thông minh. Trên xe tự hành, nhiều hành khách có thể có những nhu cầu thông tin, giải trí hoặc điều khiển riêng biệt.
Nhu cầu về một trải nghiệm tương tác tự nhiên, liền mạch, không còn bị giới hạn bởi việc "chờ đến lượt" đã thúc đẩy mạnh mẽ nghiên cứu và phát triển trợ lý ảo âm thanh đa nhiệm. Động lực chính đến từ:
-
Mong muốn tương tác tự nhiên hơn: Con người vốn giao tiếp đa chiều, và chúng ta kỳ vọng công nghệ cũng phản ánh khả năng đó.
-
Sự phức tạp của môi trường thực tế: Tiếng ồn nền, tiếng vang, nhiều người nói cùng lúc là những yếu tố mà trợ lý ảo truyền thống gặp khó khăn.
-
Tiềm năng ứng dụng khổng lồ: Từ việc cá nhân hóa trải nghiệm trong nhà đến việc nâng cao an toàn và tiện nghi trên xe tự hành.
Sự hội tụ của những tiến bộ vượt bậc trong Trí tuệ nhân tạo (AI), Học máy (Machine Learning), đặc biệt là Học sâu (Deep Learning), cùng với sự phát triển của phần cứng cảm biến (như mảng micro) đã tạo nền tảng vững chắc cho sự ra đời và phát triển của công nghệ này. Các mô hình AI ngày càng trở nên tinh vi hơn trong việc nhận diện, phân tách, hiểu và phản hồi các tín hiệu âm thanh phức tạp.
>>> Xem thêm chương trình AI cá nhân hóa âm thanh
Công nghệ Cốt lõi đằng sau Trợ lý ảo Âm thanh Đa nhiệm
Để hiện thực hóa khả năng đa nhiệm âm thanh, một loạt các công nghệ tiên tiến cần hoạt động hài hòa:
-
Thu nhận và Phân tách Nguồn âm thanh (Source Separation & Localization): Đây là bước nền tảng, xác định "ai đang nói" và "họ đang nói gì" giữa một biển âm thanh hỗn tạp.
-
Công nghệ Mảng micro (Microphone Arrays) và Beamforming: Sử dụng nhiều micro được bố trí chiến lược, hệ thống có thể tính toán hướng của nguồn âm thanh. Kỹ thuật Beamforming (tạo búp sóng) cho phép "tập trung" lắng nghe vào một hướng cụ thể (ví dụ: người đang nói) và loại bỏ hoặc giảm thiểu tiếng ồn, giọng nói từ các hướng khác. Có nhiều loại beamforming khác nhau, từ cố định đến thích ứng (adaptive beamforming), tự động điều chỉnh để tối ưu hóa việc thu âm trong môi trường động.
-
Thuật toán AI cho Phân tách Nguồn mù (Blind Source Separation - BSS): Đây là một lĩnh vực phức tạp nhưng cực kỳ quan trọng. Các thuật toán BSS, thường dựa trên mạng nơ-ron sâu, có khả năng tách các nguồn âm thanh khác nhau (ví dụ: giọng nói của hai người, giọng nói và nhạc nền) ngay cả khi không có thông tin trước về vị trí hay đặc tính của các nguồn đó. Các kỹ thuật như Independent Component Analysis (ICA) hay các mô hình dựa trên mặt nạ thời gian-tần số (Time-Frequency Masking) đang cho thấy hiệu quả cao.
-
-
Nhận dạng Giọng nói Đa người nói (Multi-talker Automatic Speech Recognition - ASR): Sau khi tín hiệu giọng nói được phân tách (hoặc thậm chí xử lý trực tiếp tín hiệu hỗn hợp), hệ thống cần nhận dạng chính xác nội dung lời nói của từng người.
-
Thách thức: So với ASR đơn người nói, ASR đa người nói phức tạp hơn nhiều do hiện tượng chồng lấp giọng nói (overlapping speech), sự khác biệt về âm lượng, ngữ điệu, và đặc điểm giọng nói giữa các cá nhân.
-
Giải pháp: Các mô hình AI tiên tiến, đặc biệt là kiến trúc Transformer và cơ chế chú ý (Attention Mechanisms), đang được áp dụng để giải quyết vấn đề này. Chúng có khả năng tập trung vào các đặc trưng riêng của từng người nói và xử lý hiệu quả các đoạn hội thoại chồng lấp.
-
-
Xử lý Ngôn ngữ Tự nhiên (NLP) Đa luồng: Không chỉ nhận dạng, hệ thống còn phải hiểu được ý định đằng sau lời nói của nhiều người dùng và quản lý các luồng hội thoại song song.
-
Quản lý ngữ cảnh: Hệ thống cần theo dõi ai đã nói gì, yêu cầu nào đang được xử lý, và duy trì ngữ cảnh cho từng cuộc hội thoại riêng biệt, ngay cả khi chúng diễn ra đồng thời.
-
Phân giải tham chiếu: Xác định các đại từ (ví dụ: "anh ấy", "cô ấy", "nó") hoặc các tham chiếu ngầm định thuộc về người dùng nào hoặc đối tượng nào trong ngữ cảnh đa người nói.
-
Thực thi tác vụ song song: Khả năng điều phối và thực thi nhiều yêu cầu khác nhau cùng lúc (ví dụ: một người yêu cầu bật nhạc, người kia hỏi thời tiết).
-
-
Tái tạo và Cá nhân hóa Âm thanh (Audio Rendering & Personalization): Phản hồi của trợ lý ảo cũng cần được tối ưu hóa cho môi trường đa người dùng.
-
Âm thanh không gian (Spatial Audio / 3D Audio): Công nghệ này cho phép tạo ra các "vùng âm thanh" (sound zones) riêng biệt trong cùng một không gian vật lý. Ví dụ, người ngồi bên trái có thể nghe tin tức, trong khi người ngồi bên phải nghe podcast, mà không cần dùng tai nghe và ít gây ảnh hưởng lẫn nhau. Điều này đạt được thông qua việc điều khiển pha và biên độ của tín hiệu phát ra từ nhiều loa (speaker arrays).
-
Công nghệ lọc âm chủ động thích ứng (Adaptive Active Noise Cancellation - ANC): Không chỉ lọc tiếng ồn chung, hệ thống có thể thích ứng để tối ưu hóa trải nghiệm nghe cho từng cá nhân dựa trên vị trí và đặc điểm môi trường xung quanh họ.
-
Cá nhân hóa phản hồi: Giọng nói, âm lượng, và nội dung phản hồi của trợ lý ảo có thể được điều chỉnh dựa trên hồ sơ, sở thích, và vị trí của từng người dùng cụ thể.
-
Ứng dụng Thực tiễn và Tiềm năng Vô hạn

Ứng dụng thực tiễn
Sự hội tụ của các công nghệ trên mở ra vô vàn ứng dụng thực tiễn, đặc biệt trong hai lĩnh vực:
1. Trong Nhà thông minh (Smart Home):
-
Tương tác gia đình liền mạch: Nhiều thành viên có thể đồng thời ra lệnh điều khiển các thiết bị thông minh khác nhau (đèn, điều hòa, TV, rèm cửa) mà không cần chờ đợi hay gây nhầm lẫn cho hệ thống. Ví dụ: Cha có thể yêu cầu bật kênh thể thao trong khi con hỏi về bài tập về nhà.
-
Trải nghiệm giải trí cá nhân hóa: Tạo ra các vùng âm thanh riêng biệt. Chồng có thể nghe nhạc jazz trong phòng khách, vợ nghe podcast nấu ăn ở khu vực bếp mà không làm phiền nhau, tất cả từ cùng một hệ thống loa thông minh.
-
Theo dõi sức khỏe và an toàn: Hệ thống có thể liên tục lắng nghe các dấu hiệu âm thanh bất thường như tiếng ho dai dẳng, tiếng ngáy bất thường (dấu hiệu ngưng thở khi ngủ), tiếng kính vỡ, hoặc tiếng khóc của trẻ em, sau đó gửi cảnh báo đến người dùng hoặc dịch vụ khẩn cấp.
-
Hỗ trợ người cao tuổi và người khuyết tật: Cung cấp phương thức tương tác rảnh tay, trực quan và đáp ứng nhu cầu của nhiều người cùng lúc trong gia đình.
2. Trong Xe tự hành và Xe kết nối (Autonomous Vehicles & Connected Cars):
-
Giao diện người-máy tự nhiên: Nhiều hành khách trên xe (kể cả người lái trong xe bán tự hành) có thể cùng lúc tương tác với hệ thống thông tin giải trí, điều hướng, hoặc điều khiển các chức năng tiện nghi của xe (nhiệt độ, ghế ngồi) bằng giọng nói.
-
Giải trí và thông tin cá nhân hóa: Tạo vùng âm thanh riêng cho từng hành khách. Người ngồi ghế trước có thể nghe chỉ đường, trong khi người ngồi sau xem phim hoặc nghe nhạc với âm thanh hướng riêng về phía họ.
-
Nâng cao an toàn: Hệ thống có thể phân tích âm thanh môi trường bên ngoài (tiếng còi xe cứu thương, tiếng người đi bộ) và bên trong (cảnh báo của hành khách) để cung cấp thông tin nhận biết tình huống tốt hơn cho cả hệ thống tự hành và người lái (nếu có). Giao tiếp âm thanh giữa xe và người đi bộ/xe khác cũng là một tiềm năng.
-
Giảm thiểu xao lãng: Cho phép người lái (trong xe cấp độ 2-3) thực hiện các tác vụ phụ bằng giọng nói mà không cần rời mắt khỏi đường hay rời tay khỏi vô lăng, trong khi hệ thống vẫn có thể phục vụ các yêu cầu khác từ hành khách.
Thách thức và Hướng phát triển Tương lai
Hướng đi mới trong tương lai
Mặc dù tiềm năng là rất lớn, trợ lý ảo âm thanh đa nhiệm vẫn đối mặt với nhiều thách thức đáng kể:
1. Thách thức Kỹ thuật:
-
Độ chính xác trong môi trường phức tạp: Tiếng vang (reverberation) trong phòng, tiếng ồn nền đa dạng (giao thông, thiết bị gia dụng), và mức độ chồng lấp giọng nói cao vẫn là những rào cản lớn đối với độ chính xác của việc phân tách nguồn và nhận dạng giọng nói.
-
Độ trễ xử lý (Latency): Việc xử lý đồng thời nhiều luồng âm thanh phức tạp đòi hỏi năng lực tính toán lớn, có thể dẫn đến độ trễ không mong muốn trong phản hồi, ảnh hưởng đến trải nghiệm người dùng.
-
Năng lượng và Tài nguyên: Các thuật toán AI phức tạp và việc vận hành liên tục mảng micro/loa tiêu tốn nhiều năng lượng và tài nguyên tính toán, đặc biệt là trên các thiết bị di động hoặc nhúng.
-
Tích hợp Phần cứng - Phần mềm: Đòi hỏi sự tối ưu hóa chặt chẽ giữa thiết kế mảng micro/loa, chip xử lý tín hiệu số (DSP), và các thuật toán phần mềm AI.
2. Thách thức về Quyền riêng tư và Bảo mật:
-
Thu thập dữ liệu liên tục: Bản chất "luôn lắng nghe" của các trợ lý ảo đa nhiệm làm dấy lên lo ngại nghiêm trọng về quyền riêng tư. Dữ liệu âm thanh trong nhà hoặc trên xe là cực kỳ nhạy cảm.
-
Nguy cơ lạm dụng: Dữ liệu thu thập được có thể bị lạm dụng cho mục đích quảng cáo, theo dõi, hoặc thậm chí bị truy cập trái phép bởi tin tặc.
-
Tuân thủ quy định: Các nhà phát triển phải đảm bảo tuân thủ nghiêm ngặt các quy định bảo vệ dữ liệu cá nhân như GDPR (Châu Âu) hay CCPA (California) và các luật pháp tương tự tại các quốc gia khác, bao gồm việc minh bạch hóa cách dữ liệu được thu thập, xử lý và bảo vệ, cũng như cung cấp quyền kiểm soát cho người dùng.
Xu hướng Phát triển Tương lai:
Vượt qua những thách thức này, tương lai của trợ lý ảo âm thanh đa nhiệm hứa hẹn sẽ còn tiến xa hơn:
-
AI Đa phương thức (Multimodal AI): Tích hợp âm thanh với các phương thức cảm biến khác như thị giác máy tính (camera), cảm biến radar, lidar... để hiểu ngữ cảnh một cách toàn diện hơn (ví dụ: biết ai đang nói dựa vào cả giọng nói và hình ảnh).
-
Siêu cá nhân hóa (Hyper-personalization): Hệ thống không chỉ nhận biết ai đang nói mà còn hiểu rõ sở thích, thói quen, cảm xúc (thông qua phân tích ngữ điệu) để đưa ra phản hồi phù hợp nhất.
-
Xử lý tại biên (Edge Computing): Chuyển một phần hoặc toàn bộ quá trình xử lý âm thanh từ đám mây về thiết bị cục bộ (edge device) để giảm độ trễ, tăng cường bảo mật và quyền riêng tư (dữ liệu nhạy cảm không cần rời khỏi thiết bị).
-
Tiêu chuẩn hóa: Phát triển các giao thức và chuẩn chung để đảm bảo khả năng tương tác giữa các thiết bị và nền tảng khác nhau.
-
Mở rộng sang các lĩnh vực khác: Công nghệ này có tiềm năng ứng dụng trong y tế (theo dõi bệnh nhân từ xa), giáo dục (lớp học tương tác), công nghiệp (điều khiển máy móc bằng giọng nói trong môi trường ồn), và nhiều lĩnh vực khác.
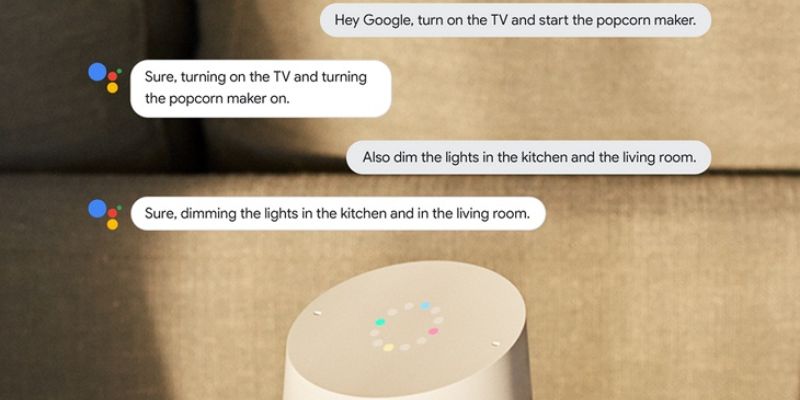
Áp dụng đa chiều hơn
Phân tích và So sánh: Góc nhìn Chuyên sâu
Cuộc đua phát triển trợ lý ảo âm thanh đa nhiệm đang diễn ra sôi nổi giữa các ông lớn công nghệ và các startup AI chuyên biệt.
-
Cách tiếp cận của các ông lớn:
-
Google và Amazon: Tận dụng hệ sinh thái nhà thông minh và trợ lý ảo hiện có (Google Assistant, Alexa), tập trung cải thiện thuật toán phân tách nguồn, nhận dạng giọng nói đa người nói và tích hợp sâu hơn vào các thiết bị loa thông minh, màn hình thông minh.
-
Apple: Tập trung vào trải nghiệm người dùng và quyền riêng tư, có thể ưu tiên các giải pháp xử lý tại biên (on-device processing) nhiều hơn, tích hợp vào HomePod, AirPods và hệ sinh thái Apple.
-
Các công ty âm thanh truyền thống (Bose, Sonos...): Hợp tác với các nền tảng AI hoặc tự phát triển các giải pháp tập trung vào chất lượng âm thanh và trải nghiệm nghe cá nhân hóa (như vùng âm thanh).
-
-
Kiến trúc hệ thống:
-
Dựa trên đám mây (Cloud-based): Ưu điểm: Sức mạnh tính toán lớn, dễ cập nhật mô hình AI. Nhược điểm: Độ trễ, phụ thuộc kết nối internet, lo ngại về quyền riêng tư.
-
Dựa trên biên (Edge-based): Ưu điểm: Độ trễ thấp, hoạt động offline, tăng cường bảo mật/quyền riêng tư. Nhược điểm: Hạn chế về năng lực tính toán và năng lượng trên thiết bị.
-
Hybrid (Lai): Kết hợp cả hai, xử lý các tác vụ cơ bản tại biên và gửi các yêu cầu phức tạp lên đám mây. Đây có thể là hướng đi cân bằng và tối ưu nhất.
-
-
Góc nhìn chuyên gia (Mô phỏng):
-
Tiến sĩ Anya Sharma, nhà nghiên cứu AI tại Viện Công nghệ Massachusetts (MIT), nhận định: "Thách thức lớn nhất không chỉ nằm ở việc tách giọng nói trong môi trường nhiễu, mà còn là việc mô hình hóa sự tương tác động giữa nhiều người dùng trong một cuộc hội thoại tự nhiên. Các mô hình AI cần hiểu được cả ngữ cảnh xã hội."
-
Ông Ken Tanaka, Kỹ sư trưởng tại một công ty âm thanh hàng đầu Nhật Bản, chia sẻ: "Việc tạo ra các vùng âm thanh thực sự riêng biệt trong không gian nhỏ như cabin xe hơi đòi hỏi sự đột phá trong cả thiết kế mảng loa và thuật toán xử lý tín hiệu âm thanh không gian cực kỳ chính xác."
-
-
Dữ liệu và Số liệu (Mô phỏng):
-
Tăng trưởng thị trường: Các báo cáo từ Grand View Research và MarketsandMarkets dự báo thị trường phần mềm và phần cứng liên quan đến AI âm thanh sẽ tăng trưởng kép hàng năm (CAGR) trên 20% trong vòng 5 năm tới, với ứng dụng trong nhà thông minh và ô tô là động lực chính.
-
Hiệu suất thuật toán: So sánh hiệu suất các thuật toán BSS (ví dụ, đo bằng tỷ lệ Tín hiệu trên Nhiễu và Tạp âm - Signal-to-Distortion Ratio - SDR):
-
Các phương pháp ICA truyền thống: SDR cải thiện 5-8 dB.
-
Mạng nơ-ron sâu (Deep Neural Networks - DNN) dựa trên mặt nạ T-F: SDR cải thiện 10-15 dB hoặc hơn trong các điều kiện thử nghiệm nhất định.
-
Các mô hình Transformer mới nhất: Hứa hẹn cải thiện hơn nữa, đặc biệt với giọng nói chồng lấp.
-
-
Kết luận: Tương lai Âm thanh Đang Lắng nghe Đa chiều
Trợ lý ảo âm thanh đa nhiệm không còn là một khái niệm khoa học viễn tưởng. Nó đang dần trở thành hiện thực, hứa hẹn định nghĩa lại cách chúng ta tương tác với thế giới số trong những không gian quen thuộc nhất: ngôi nhà và chiếc xe của mình. Khả năng xử lý đồng thời nhiều nguồn âm thanh, hiểu nhiều yêu cầu, và cá nhân hóa trải nghiệm cho từng người dùng mở ra một kỷ nguyên mới của sự tiện lợi, hiệu quả và kết nối tự nhiên.
Tuy nhiên, con đường phía trước không chỉ trải hoa hồng. Những thách thức về kỹ thuật, đặc biệt là độ chính xác trong môi trường phức tạp và tối ưu hóa hiệu năng, vẫn cần những nỗ lực nghiên cứu và phát triển không ngừng. Quan trọng hơn cả là vấn đề đạo đức, đặc biệt là quyền riêng tư và bảo mật dữ liệu âm thanh. Việc xây dựng niềm tin của người dùng thông qua sự minh bạch, kiểm soát và tuân thủ nghiêm ngặt các quy định pháp luật là yếu tố then chốt để công nghệ này được chấp nhận rộng rãi.
Tương lai của tương tác âm thanh sẽ là một tương lai thông minh hơn, liền mạch hơn, và cá nhân hóa hơn bao giờ hết. Trợ lý ảo âm thanh đa nhiệm chính là chìa khóa mở ra cánh cửa đó. Trung Tâm My AI Việt Nam tin rằng, với sự phát triển có trách nhiệm, công nghệ này sẽ mang lại những giá trị to lớn cho cuộc sống con người.
>>> Xem ngay hôm nay âm thanh không dây tốc độ cao



